
เริ่มจากมี HR ทักหาใน LinkedIn ว่าสนใจมาทำงาน Data Visualization ด้วยกันไหม ?
สิ่งที่เราเอ้ะ ! เพราะโดยปกติแล้ว บริษัทมักจะมองหา Data Analyst มากกว่า หรือถ้าชัดว่าต้องการทักษะ Data Visualization เป็นสำคัญก็ควรมองหา Business Intelligist ที่ฟังดูเป็นตำแหน่งงานมากกว่า และมารู้ภายหลังต้องเป็นทีม Data คนเดียวของบริษัท (สำหรับทีมที่อยู่ในไทย) !
หลังจากพูดคุยกัน ในเนื้องานหลัก ๆ ก็ไม่ค่อยน่ากังวลใจเท่าไหร่ แต่ก็ยังนึกไม่ค่อยออกว่าแล้วถ้าต้องทำงานคนเดียว ในสโคปที่ดูเหมือนจะไม่ใช่แค่ Data Visualization อย่างเดียว แล้วเราคนเดียวจะจบงานได้จริงหรือ ?
สำหรับความคาดหวังของทีมในตอนนั้นที่คุยกัน คือ เราในฐานะคนทำข้อมูลต้องช่วยจัดการฐานข้อมูลให้สามารถนำไปใช้วิเคราะห์ต่อได้ สามารถช่วยให้การตัดสินจากทีมและลูกค้าอยู่บนพื้นฐานของข้อมูลแทนความรู้สึก และสามารถเพิ่มมูลค่าของข้อมูลเพื่อเป็นโมเดลทำเงินจากลูกค้าในอนาคต
พอถึงจุดที่ตัดสินใจว่าทั้งเราและทีมตกลงว่าจะทดลองทำสิ่งนี้ไปด้วยกัน ในหัวก็คิดถึงความเป็นไปได้และกระบวนการทำงานคร่าว ๆ แต่ก็มีความกังวลในเรื่อง
- เมื่อไม่มี Data Engineer เราต้องเตรียมข้อมูลเอง จึงไม่สามารถเลี่ยงงาน Database ได้ แล้ว Data Storage, Data Pipeline ล่ะต้องทำยังไง ?
- เมื่อไม่มี Data Scientist ก็แปลว่าไม่ต้องทำส่วน Model Developement รึเปล่านะ ?
- เมื่อไม่มี Data Analyst แต่ Visualization ก็เป็นส่วนหนึ่งของหน้าที่นี้ งั้นขอบเขตของงานน่าจะลื่นไหลไปทำส่วนอื่น ๆ ด้วยรึเปล่านะ ?
- เมื่อไม่มี Head of Data แล้วการตัดสินใจในการทำงานต่อ ๆ ไป เราจะรู้ได้ไงว่าถูกทางแล้ว
Disclaimer
เหตุการณ์ทั้งหมดเป็นเหตุการณ์สมมติที่ถูกดัดแปลงจากประสบการณ์จริงของคน ๆ หนึ่งของการทำงานเป็นทีม Data คนเดียวของบริษัท โดยนำเสนอในรูปแบบ Diary 1 ปี
Day 1 วันแรกของการศึกษางานเก่า ๆ และสำรวจการใช้ข้อมูลของคนในบริษัท
วันแรกของการทำงานที่บริษัทเอกชนแห่งหนึ่งที่ทำด้านการตลาดที่ริเริ่มจ้าง Data Analyst มาช่วยทีม Marketing ทำงาน
เราในฐานะที่เป็นคนใหม่ เราเลยอยากจะทำความเข้าใจกับภาพรวมในงานทั้งหมด เลยขอดูงานเก่า ๆ พร้อมถามความเห็นของคนในทีมต่องานนั้น ๆ พอให้เข้าใจความคาดหวังของทีมได้บ้าง อีกทั้งก็เห็นจุดที่อยากทำให้ดีขึ้น พอเริ่มรู้ปัญหาแล้ว งั้นลองมาสอบถามคนในทีมอีกครั้งว่ามีความคาดหวังระยะสั้นและระยะยาวอย่างไร ?
สรุปงานที่ทำในวันนี้
เพื่อให้เราสามารถตัดสินใจวางแผนการทำงานในอนาคตของเราได้ระหว่างรอตัวอย่างข้อมูลและการขออนุญาตใช้ข้อมูลลูกค้าที่ต้องใช้ทำงาน
โดยสิ่งที่เราทำก็คือ
- สอบถามความคาดหวังจากเพื่อนร่วมงานในฐานะของการมีคนช่วยทำงานข้อมูล
- แหล่งข้อมูลมีอะไรบ้าง ได้มาจากไหน ?
- บันทึกสิ่งที่ทีมมีจากงานเก่า ๆ เพื่อดูว่าอะไรที่ดีแล้วและดีได้มากกว่านี้ พร้อมจัดความสำคัญของงานเหล่านั้นเช่น ลำดับตามความสำคัญแบบ MoSCoW Prioritization

Day 2 วันที่ได้เห็นไฟล์ข้อมูลในปัจจุบันที่ใช้งานจริง ๆ มาเป็นตาราง Excel แบบ Too Many Information
Excel คือโปรแกรมคำนวณที่ประยุกต์ให้ใช้เป็นรายงานได้ บริษัทก็มักใช้ Excel สารพัดประโยชน์ทั้งเขียน ทั้งคำนวณ ทำกราฟ เทคโน๊ต ครั้งนี้ก็เช่นกันแม้แต่คนทำไฟล์นี้ขึ้นมาก็สับสนกับข้อมูลที่ตัวเองทำ บ้างล็อกเซลล์ผูกสูตรเอาไว้ บ้างกรอกตัวเลขเอง บ้างเขียนโน๊ต มีที่แอบโน๊ตคำนวณแทรกไว้ด้วย
บ่อยเลยที่เจอ Merged Cell ไว้ เวลาส่งต่อไฟล์ไปให้คนอื่นทำงานต่อก็จะเจอปัญหาการคำนวณผิด หาข้อมูลไม่เจอ พบ Error ต้องใช้เวลาทำความเข้าใจกับข้อมูลนานเกินไป สำคัญสุดคือไม่สามารถนำเอาข้อมูลรูปแบบไปใช้ในการวิเคราะห์ข้อมูลได้
สรุปงานที่ทำในวันนี้
วันนี้เราจะทำ 2 อย่างคือหนึ่ง Re design ข้อมูลนี้ให้อ่านง่ายขึ้น สองเปลี่ยนให้อยู่ในรูปแบบที่สามารถนำไปใช้วิเคราะห์ต่อได้
โดยสิ่งที่เราทำก็คือ
- Cleansing Data จัดการลบ Cell ที่ Merge ออก
- จัด Data Type แยกข้อมูลที่เป็นตัวเลข ข้อมูลที่เป็นข้อความใน Header
- ชีทที่อยู่ในรูปแบบ Pivot Table (ซึ่งอ่านง่าย แต่คนทำข้อมูลเอาไปใช้ยาก) จัดให้เป็น Single Table (รายละเอียดเชิงลึก อ่านต่อได้ที่ รู้จัก Machine readable format แนวทางการจัดเก็บข้อมูลที่วิเคราะห์ต่อง่าย และ คนใช้ข้อมูลชอบ) โดยการ
- ลบคอลัมน์ที่เป็น Summary ออก
- ลบ Headline ที่ไม่จำเป็นและยกเลิกการ Merge Cell
- ถ้าไม่ต้องการให้มี Formula ให้ Copy และ Press value only
- ทำให้อยู่ในรูปแบบ Tabular ด้วยการทำ Unpivot Table และเลือก Row ให้ถูกต้อง เช่น เลือกให้ Row “อายุ” อยู่ใน Column “อายุ”
- แยก Metrics ที่เป็น Calculated Formula Metrics เช่น ROI ซึ่งมาจากการคำนวน (Net Profit / Total Investment) * 100 และ Isolated Metrics เช่น Number of Visits เป็นต้น เพื่อให้ส่วนที่เป็น Calculated Metrics เด่นขึ้นมาให้เราสามารถเช็คความถูกต้องดูอีกครั้ง เพราะตรงนี้ผิดเยอะมาก

Day 7 วันที่ต้องทำความรู้จักทุก ๆ คนว่าทำงานประจำวันอย่างไรเพื่อค้นหาต้นสายข้อมูล
หลังจากที่ได้พอรู้ว่างานของเราเป็นประมาณไหน กับกองข้อมูลมหาศาลที่รอการรื้อฟื้นให้ใช้งาน ก็มีบางอย่างที่เราอยากลองทำความเข้าใจสักหน่อย ในใจลึก ๆ ก็อยากหาวิธีให้เราลดเวลาการทำ Data Preparation ลง จึงเริ่มต้นจากการลองทำความรู้จักกับเพื่อนใหม่เพื่อหวังว่าจะเจอวิธีที่ว่า
สรุปงานที่ทำในวันนี้
ในวันที่สองนี้เราเริ่มต้นจากการสอบถามงานประจำวันของเพื่อนร่วมงานเพื่อให้รู้ว่ากว่าจะมาเป็นข้อมูลให้เราใช้แบบนี้มีที่มาที่ไปยังไง และระวังไม่ให้เราไปทำให้กระบวนการทำงานเดิมของเพื่อนร่วมงานยุ่งยากมากเกินไป
โดยสิ่งที่เราทำก็คือ
- ทำความรู้จักกับงานของเพื่อนร่วมงานให้มากที่สุด
- รู้ว่ากระบวนการไหนเกิดการบันทึกข้อมูลและข้อมูลถูกส่งต่อให้ใคร
- รู้ว่าจะนำไปใช้ต่อยังไง ผลลัพธ์เป็นแบบไหน
- ลองวาด workflow ออกมาเพื่อดูจุดที่อยากจะปรับปรุงการเก็บข้อมูลให้ทำง่ายได้สะดวกขึ้นในอนาคต
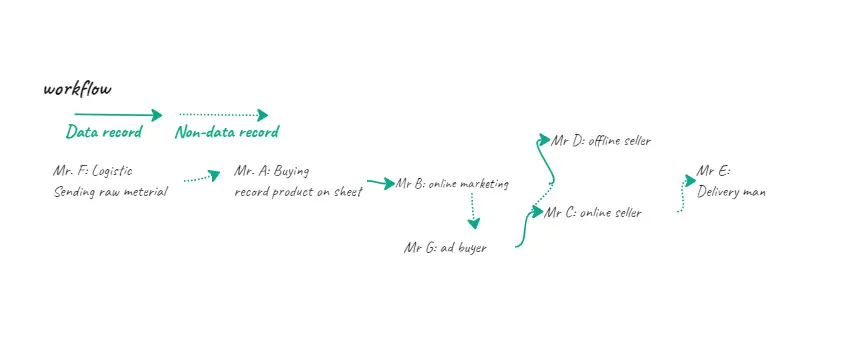
Day 8 สัปดาห์แห่งการเฝ้าสังเกตการณ์ในห้องประชุม (ออนไลน์)
ในแต่ละวันจะมีการประชุมเพื่ออัพเดตข้อมูลให้ทั้งคนในและคนนอก ยิ่งถ้าเรามาใหม่แล้วไม่คุ้นเคยกับข้อมูลของบริษัท โอกาสนี้เป็นจังหวะสำคัญที่เราจะได้เห็นภาพการทำงานที่ชัด ภาษาที่ใช้สื่อสาร ศัพท์เทคนิคในวงการที่คนทำงานข้อมูลอย่างเรารู้แล้วจะทำให้เราเข้าใจงานมากขึ้น ที่สำคัญเราจะได้เห็นความต้องการของลูกค้าผ่านสิ่งที่พวกเขาอยากรู้ คำถาม และรูปแบบในการนำเสนอของทีมเรา วันนี้เราเลยขอ Meeting Calendar จากทุกคน และเข้าประชุมตามวาระที่เกี่ยวกับข้อมูล และติดตามการทำงานของทุกคน (ที่ใช้ข้อมูล) หนึ่งสัปดาห์ เพื่อลองสร้าง user persona
สิ่งที่ได้เรียนรู้ในวันนี้
- ในการประชุมเพื่อนร่วมงานเรา มักจะต้องเป็นคนนำเสนอข้อมูลให้พยายามจด Metric ที่ทีมของเราใช้บ่อย และสังเกตเงื่อนไขการวิเคราะห์ข้อมูล เพื่อนำไปปรับปรุงงานให้ตอบโจทย์อีกที
- ถ้าได้มีโอกาสประชุมกับลูกค้าให้ สังเกตผู้ฟัง โดยเฉพาะลูกค้าที่ชอบให้ความเห็นเพราะมีโอกาสสูงที่ลูกค้าคนนั้นจะมีอำนาจตัดสินใจที่อาจจะเป็น Key Stakeholder หรือ Key Decision Maker ซึ่งในอนาคตงานข้อมูลของเราน่าจะเกี่ยวข้องกับเขามากที่สุด ข้อสังเกตอีกอย่างพวกเขาเหล่านั้นมักเป็นระดับ C Level, Director, Manager หรือคนทำงานที่ใกล้ชิดอย่าง Sales, Marketers โดยสิ่งที่เราต้องฟังคือลูกค้าของเราให้ความสำคัญกับข้อมูลอะไร ผ่านการตั้งคำถามของลูกค้า
Day 16 วันที่ต้องออกแบบแดชบอร์ดโดยที่ไม่ได้มี Designer ก็สนุกดีเหมือนกัน
ด้วยข้อจำกัดของเวลา ทำให้ Data Analyst อย่างเรามักคำนึงถึงความครบถ้วนของข้อมูลมาก่อน เช่น ในการสร้าง Dashboard ที่เน้นข้อมูลแน่น ๆ เราอาจคิดว่า นี่คือการให้ความสำคัญกับ Functionality แต่จริง ๆ แล้วข้อมูลอัดเต็ม Dashboard ไม่เท่ากับ Functionality สำหรับงาน Data Visualization ต้องการมีการวาง Element ที่ให้การทำงานของกราฟ ตาราง และการ์ดประสานกัน การใช้ Filter อย่างเหมาะสม จะช่วยลดเวลาอ่านข้อมูลของลูกค้าของเรา นั่นคือการทำให้ Functionality สมบูรณ์ เราจึงต้องทำดีไซน์ยังไงก็ได้ให้อ่านข้อมูลลื่นไหลและเคารพเวลาการอ่านข้อมูลของลูกค้า
สรุปงานที่ทำในวันนี้
ออกแบบแดชบอร์ดให้ทำงานได้อย่างมีประสิทธิภาพ
โดยสิ่งที่เราทำก็คือ
- ใช้ https://balsamiq.com/ ดีไซน์แดชบอร์ดออกมาให้ทีมดู ที่ใช้โปรแกรมนี้เพราะมี UI น่ารักจะได้เป็นมิตรกับการใช้งานแบบนี้ครั้งแรก
- ทำเสร็จก็ไปเช็คว่าข้อมูลสำคัญ ๆ ยังอยู่ครบ พร้อมกับส่งต่อให้ทีมเห็นโครงร่างก่อน
- ลงมือทำงานกับข้อมูลจริงและสร้างแดชบอร์ดจริงบน BI Tool
- ตรวจสอบฟังก์ชันของแดชบอร์ดทั้งหมด การทำงานของทุก Elements บนแดชบอร์ด เช็คลิสความสมบูรณ์ของข้อมูลว่ายังคงสื่อสารได้เหมือนกับงานต้นฉบับ
- ออกแบบวิธีการเช็คคุณภาพของสิ่งที่ได้ทำ เช่น ระยะเวลาการนำเสนองานแบบเก่าเทียบกับแบบใหม่
💡 Tip & Trick: อย่าพยายามเปลี่ยนให้วิธีการเดิมที่คนเก่าทำไว้ในทันที พอมองกลับไปในวันแรกที่เราพยายามเปลี่ยนแปลงให้เป็นการนำเสนอข้อมูลแบบใหม่แล้วพบว่า ของเดิมก็ไม่ได้แย่เสมอไปเพราะเหตุผลที่หลาย ๆ ที่ยังใช้ไฟล์ Excel อัดแน่นด้วยข้อมูลแบบนี้เพราะสะดวกต่อการทำงาน แก้งาน แล้วยังใช้พรีเซ็นต์ได้ด้วย แต่ก็ต้องแลกมาด้วยระยะเวลาและองค์กรก็ต้องยึดติดกับคนทำงานมากกว่าระบบ
ดังนั้นในวันที่เราสามารถหาสมดุลเจอก็ใช้วิธีลดจำนวนรายงานแบบนี้ลง สำหรับพวก Ad-hoc Report ก็ใช้การดึงข้อมูลไปทำใน BI Tool แทน ส่วนที่ต้องเป็นรายงานฉบับเต็มก็ใช้วิธีดึงข้อมูลไปวางบนไฟล์ Excel อันเดิมที่ทุกคนคุ้นเคยดี
Day 26 วันที่ลองให้ User ใช้แดชบอร์ดเป็นครั้งแรก
เราได้เคยทำแดชบอร์ดอยู่หลายครั้ง บางครั้งก็มีผู้ใช้งานมีส่วนร่วมในการออกแบบด้วย ซึ่งเป็นเรื่องที่ดีมากเพราะมั่นใจได้ว่าผู้ใช้งานของเราจะเข้าใจฟังก์ชันได้เป็นอย่างดี แต่ก็มีหลาย ๆ ครั้งที่เราต้องออกแบบเพียงลำพัง แล้วค่อย ๆ ปรับให้ฟังก์ชันตรงกับผู้ใช้งาน สำหรับในครั้งนี้ต่างออกไปเพราะผู้ใช้งานของเรานี้ ไม่เคยใช้แดชบอร์ดมาก่อนเลย พวกเขาคุ้นเคยกับกระดาน Excel มากกว่า ดังนั้นความคาดหวังส่วนใหญ่คือต้องการเห็นข้อมูลทุกอย่างที่ควรมีใน Excel มีบนแดชบอร์ดอันใหม่
จากประสบการณ์การทำแดชบอร์ดของเรา เราสามารถออกแบบให้ข้อมูลทั้งหมดใน Excel นั้นไปอยู่บนแดชบอร์ดได้แต่เพื่อลดระยะเวลาการเพ่งข้อมูลเราจึงออกแบบให้แดชบอร์ดทำงานจากข้อมูลภาพใหญ่แล้วค่อย Drill down ไปข้อมูลย่อย แต่การออกแบบนี้จะต้องเปลี่ยนพฤติกรรมการอ่านข้อมูลของผู้ใช้งานบางคนไปเพราะเขาจะมองไม่เห็นข้อมูลทั้งหมดในครั้งเดียว แล้วฟังก์ชันในแดชบอร์ดที่เราออกแบบไว้อาจถูกมองข้าม ดังนั้นเราจึงลองนำเอาไอเดียของ Test Case Scenario มาประยุกต์ใช้กับกับการสร้าง Dashboard ในการแนะนำการใช้งาน (Dashboard ไม่เหมือน Report ตรงที่มันอาจจะต้องกดนั่น คลิกนั่น เพื่อให้เห็นข้อมูลตามต้องการ)
สรุปงานที่ทำในวันนี้
ทดลองการใช้งาน Dashboard ด้วย Test Case Scenario
โดยสิ่งที่เราทำก็คือ
- เขียน Scenario ให้สอดคล้องกับฟังก์ชันของ Dashboard เช่น ลำดับข้อมูลที่เป็นหัวข้อใหญ่ ๆ และหัวข้อย่อยตาม Sitemap
- อธิบายกราฟและตารางข้อมูลที่ใช้ในแต่ละเอียดให้ละเอียด เช่น กราฟสัดส่วนยอดขายประจำปีใช้ Pie Chart ที่แบ่ง Categories สินค้าแบบ Top 5 ส่วนลำดับที่ 6 เป็นต้นมาจะจัดให้อยู่ใน Other Cate. เป็นต้น
- อธิบายฟังก์ชัน Drill down ที่ทำไว้
- อธิบายฟังก์ชัน Filter ว่าทำงานกับ Sitemap ไหนบ้าง, Condition ของ Filter เป็นอย่างไร
ตัวอย่างของ Test Case
| Scenario | Step | Expected Results | Status (Pass/Fail) | Additional Note: |
|---|---|---|---|---|
| สรุปยอดขายประจำปี | – | KPIs Card : ตัวเลขยอดขายทั้งหมด และแบบการ์ดที่มีการเปรียบเทียบกับปีก่อนหน้าแบบ YoY growth | Pass | |
| สรุปยอดขายตามประเภทของสินค้าประจำปี | – | Pie chart: 5 Cate. + Other | Pass | ขอเพิ่มเป็น 6 Cate. ได้ไหม ? 😂 |
💡 Tip & Trick: ผู้ใช้งานจะต้องได้ลองเล่นแดชบอร์ดด้วยตัวเองในทุก ๆ ฟังก์ชันเพราะต้องทดสอบตาม Test Case ดังนั้นนอกจากจะเป็นการบอกฟังก์ชันของแดชบอร์ดแล้วยังช่วยให้ผู้ใช้งานได้สำรวจความต้องการของตนเองด้วยเพื่อให้เราได้ Insight การใช้งานเพื่อปรับปรุงแดชบอร์ดของเราให้ตอบโจทย์ผู้ใช้งานได้ดีขึ้น
Day 30 วันที่ต้องแก้ Excel โครตสูตรพันปีให้กลับมาอัพเดตในปัจจุบัน
เชื่อว่าคนทำงานหลาย ๆ คนมักไม่ชอบงานแก้ ยิ่งเป็นงานแก้ที่เป็นไฟล์ Excel แบบหนัก ๆ, ตารางซ้อนตาราง หรือการ Merge Cell เพื่อความสวยงามต่อการพรีเซ้นต์แต่ไม่ดีต่อการคำนวณ
ยิ่งไปกว่านั้นข้อมูลที่ถูก Hard code ในแต่ละช่อง และการเขียนสูตรที่ล็อกเซลล์ผิดช่อง แต่ก็มีผู้ใช้งานที่ไม่ได้จับสังเกตก็ใช้ชีทนี้ต่อตามความคุ้นชิน โดยที่อาจไม่รู้เลยว่าผลลัพธ์ที่ออกมาจะไม่ถูกต้อง
สรุปงานที่ทำในวันนี้
งั้นวันนี้ลองตั้งสติแล้วเริ่มต้นจากหารูปแบบ (Pattern) ความผิดปกติที่เป็นไปได้ แล้วค่อยไล่แก้ไขทีละจุดอย่างมีกลยุทธ์ (คิดว่านะ 😅)
โดยสิ่งที่เราทำก็คือ
- แก้ทีละอย่างเริ่มจากยกเลิกการผูกเซลล์
- ใช้ฟิลเตอร์เพื่อหารูปแบบตัวแปรทั้งหมด
- จัดการทีละสูตรจนครบ
- อัพเดตข้อมูลใหม่ที่จะเพิ่มลงไป พยายามให้ลด Hard Code ที่ไม่จำเป็น ส่วนไหนที่ต้อง Hard Code ต้อง Highlight ไว้ เช่น ตัวเลข %MV KPI ของเดือนตุลาคมเป็นต้น
- สุดท้ายบันทึกเวอร์ชั่นของไฟล์
- อย่าลืม Backup file !
- ตั้งค่าการเข้าถึงให้เฉพาะผู้ที่มีสิทธิ์เท่านั้น
แล้ววันแห่งการแก้งาน (คนอื่น) ก็ผ่านไป
Day 50 วันทั้งวันมีแต่ SQL
SQL อย่างเดียวก็จบงานได้ ส่วนใหญ่แล้วเราต้องทำงานกับ Relational Database ดังนั้นงานหลักเราคือ Extract Data และ Query Data ที่สำคัญ ๆ เพื่อทำงานต่อเช่น ทำ Ad-hoc Report, ทำแดชบอร์ด หรือทดสอบค่าสถิติ
การรู้พื้นฐานการเขียน SQL จึงสำคัญมากไม่ว่าจะใช้งานกับฐานข้อมูล SQL Software และ Cloud Services ที่ใช้กันหลาย ๆ ที่น่าจะประกอบด้วย Microsoft SQL Server, MySQL, PostgreSQL, SQLite, Snowflake Google Cloud, Microsoft Azure, SQL Database, Amazon RDS
สรุปงานที่ทำในวันนี้
ปิด Task Tickets ด้วย SQL
โดยสิ่งที่เราทำก็คือ
- ทำ Data Retrieval เราใช้ SQL เพื่อดึงข้อมูลจากฐานข้อมูลที่เป็น Relational database ที่ต้องใช้ในวันนี้
- ทำ Data Cleaning and Transformation ข้อมูลส่วนใหญ่มีน้อยครั้งที่นำไปใช้งานได้เลย ส่วนใหญ่ต้อง Cleansing เช่น จัดการ Missing value, Remove duplicate และต้อง Transformation เช่น Custom date format, Normalization value เรามักจะทำกับข้อมูลในส่วนที่ต้องนำไปใช้งานต่อ
- ทำ Exploratory Data Analysis (EDA) ซึ่งพื้นฐานของ SQL สามารถช่วยงาน Preliminary visualizations ที่ช่วยให้นำผลลัพธ์ไปใช้ต่อได้เลยอย่างคำสั่ง Aggregation ที่ทำให้ได้ตัวเลขทางสถิติอย่างง่าย ๆ เช่น ยอดขายสินค้าประเภทเครื่องใช้ไฟฟ้าประจำเดือนมีนาคมของทุกปีเป็นต้น อย่างต่อมาคือการช่วยจัดอันดับ (Ranking) หรือลำดับ (Ordering) เช่นจัดอันดับ 10 สินค้าขายดีประจำเดือนกันยายนเป็นต้น อีกอย่างคือ Data Quality Checking เช่นการหาข้อมูลผิดปกติ (Outlier) ก่อนนำข้อมูลไปวิเคราะห์
- Data Maintenance อย่างการ CRUD data ให้ฐานข้อมูลสอดคล้องกับ Business ของเราอยู่เสมอ
- เขียน Ad hoc queries เราก็มักจะได้คำขอให้ส่งข้อมูลกับทีมอยู่บ่อยครั้ง เราจึงต้องเขียนคำสั่งให้ดึงข้อมูลที่เจาะจงเป็นไฟล์ Excel เพื่อให้คนอื่นทำงานต่อ
Day 60 วันที่ต้องหาคำตอบว่าทำไมข้อมูลไม่ตรง
ปัญหานี้เคยเกิดขึ้นตอนที่ยังไม่เคยตกลงกระบวนการทำข้อมูลของเราให้เป็นมาตรฐานเดียวกัน ก่อนหน้านี้เราต้องทำงานกับหลาย ๆ ทีม ซึ่งแต่ละทีมมักจะมีเงื่อนไขการใช้ข้อมูลที่ต่างกัน เช่น dashboard ของทีม A ต้องการให้จัดว่าเครื่องปริ้นเตอร์อยู่ในหมวดเครื่องใช้ไฟฟ้า แต่ทีม B ต้องการให้อยู่ในหมวดเครื่องใช้ในสำนักงาน ทีนี้เมื่อทีม A ต้องการข้อมูลบางอย่างที่ทีมตัวเองไม่มีเลยไปขอทีม B แล้วลองเช็คข้อมูลอื่นเล่น ๆ ปรากฎว่ายอดขายของหมวดเครื่องใช้ไฟฟ้าไม่ตรงกับหน้าแดชบอร์ดของตัวเอง ทีนี้คนทำข้อมูลจะต้องตอบคำถามให้ได้
สิ่งที่ได้เรียนรู้ในวันนี้
เพื่อจะแก้ปัญหาชวนปวดหัวแบบนี้ให้หมดไป ในตอนทำ Ac-hoc Analysis Report เราต้องทำข้อตกลงการใช้ข้อมูลร่วมกันและหมายเหตุข้อมูลที่แตกต่างกันในแต่ละ Report เพื่อแก้ปัญหาข้อมูลไม่ตรงกัน
โดยสิ่งที่เราทำก็คือ
- ตกลง Weekly Report กำหนดวันเริ่มวันอาทิตย์จบวันเสาร์ และข้อมูลแสดงถึงเวลา x.xx
- ฐานข้อมูลที่ใช้ใน Report จาก Source ไหนบ้าง อะไรที่ไม่มี Permission ต้องแจ้งก่อน
- ข้อมูลอะไรที่จะ Remove จาก Report แต่ยังปรากฎอยู่ใน Data Source
- ข้อมูลอะไรบ้างที่จะต้องการ Custom Value เช่น วิธีการเรียกชื่อที่ต้องการใช้ (Alias Name) แทนชื่อที่อยู่ในตารางข้อมูล (Table Name)
- ตกลงการใช้สูตรการคำนวณ Calculation Metrics
- ส่วนที่เปลี่ยนแปลงต้องหมายเหตุในรายงาน เช่น ค่าเงินบาท ณ เดือน X
Day 70 วันที่ลองทำ Data Team Playbook เพื่อสื่อสารกับทีม
กว่าจะมาเป็นข้อมูลที่อ่านได้ มีขั้นตอนการจัดการกับข้อมูลหลายอย่าง บางอย่างคือกฎที่ร่วมกันสร้างขึ้น บางอย่างคือสิ่งที่ผู้ทำข้อมูลตัดสินใจทำเอง ซึ่งก็มักจะเจอกับเหตุการณ์ที่ข้อมูลไม่ตรง จนทีมต้องขอ Raw Data เพื่อไปตรวจสอบกันเอง ทำให้เราต้องใช้เวลากับการตรวจสอบเยอะมาก
ดังนั้นเราจึงต้องลองออกแบบ Playbook ขึ้นมาเพื่อให้เราทำงานได้ง่ายขึ้นและคนนำข้อมูลไปใช้ก็มั่นใจมากขึ้น โดย Data Playbook คือ เอกสารที่รวบรวมกฎ ข้อตกลงที่เกี่ยวกับข้อมูลในธุรกิจของเรา เปรียบเทียบได้กับรัฐธรรมนูญด้านข้อมูลของบริษัท เราสามารถทำฉบับลูกแยกตามสาระสำคัญอย่างเช่น Data Standard Playbook ที่มีเนื้อหาเกี่ยวกับการตั้งชื่อคอลัมน์, Taxonomy เป็นต้น
เราหาความรู้เพิ่มเติมจาก Data Quality Rule ที่เน้นการควบคุม Data Quality จาก Business Use Case เพื่อประยุกต์ในการทำ Playbook ให้กับทีม
สรุปงานที่ทำในวันนี้
สร้าง Data Team Playbook เพื่อให้คุยงานได้เข้าใจกันมากขึ้นและตรวจสอบได้
โดยสิ่งที่เราทำก็คือ
- รวบรวมคำถามที่เจอกับข้อมูลบ่อย ๆ
- ตกลงการออกแบบ Action Plan ของงานแต่ละส่วนเช่น Data Requirement Analysis, Data Profiling, Data Standard (Metadata Management)
- นำ Playbook นี้ไว้บน GitHub กับ Google Sheet
Day 75 วันที่ได้เคาะสกิล Programming ที่ห่างหายไป
ก่อนเข้ามาทำงานสายเดต้า หลาย ๆ คนน่าจะเคยเรียนโค้ดดิ้งกันมาบ้าง ซึ่งใน Job Description มักจะระบุสกิลเหล่านี้แต่ในบางบริษัทก็อาจจะไม่ค่อยได้ใช้ แต่บางจังหวะที่ต้องใช้ ก็มาในตอนที่เราหลง ๆ ลืม ๆ ไปแล้ว ซึ่งในโปรเจคใหม่นี้ที่ต้องใช้สกิล R Programming สำหรับผู้อ่านที่อาจต้องเจอจังหวะแบบนี้ในภาษาอื่นก็น่าจะปรับใช้ได้เช่นกัน 🙂
สรุปงานที่ทำในวันนี้
คิดโปรเจคต่อจากทีมอื่นด้วย R Source Code ที่ถูกส่งต่อมา
โดยสิ่งที่เราทำก็คือ
- อ่าน Code Review เช่น Comment และ R Packages ที่ต้องติดตั้ง หรือถ้ามีไฟล์ Readme มาให้ด้วยก็ดูว่าโปรเจคเกี่ยวกับอะไร, วิธีการใช้ รวมถึง dependencies required ที่บางทีก็มี
- ติดตั้ง IDE เช่น R studio หรือใช้ Jupyter Notebook ก็ได้
- ที่สำคัญคือควร Run code line by line หรือทีละก้อน Comment ดีกว่า Run ทั้งโปรเจคเพื่อให้เข้าใจที่ละส่วนว่าทำงานอย่างไร
- ถ้าเจอ Error ก็ Debug ด้วยเครื่องมือ Debug() ถ้าเจออะไรที่ต้องโน๊ตไว้ก็ Comment ไว้เผื่อตอนทำงานหรือส่งต่อให้คนอื่น
- ถ้าคุ้นเคยกับโค้ดแล้ว ก็ได้เวลาใช้โค้ดต่อหรือลองหยิบ Sample Data มาลองรันดู
- เมื่อได้ผลลัพธ์แล้วก็อย่าลืม Back-up และใช้ Version Control อย่าง Git เพื่อบันทึกเวอร์ชัน
Day 100 วันที่จบงานด้วย Excel และ Spreadsheet
ถ้าขนาดข้อมูลไม่ใหญ่เกิน 30,000 row (แล้วแต่ดุลยพินิจของผู้ทำข้อมูลนะ) ที่ยังเปิดได้ปกติบนเครื่องคอม และไม่ต้องการทำโมเดลที่ซับซ้อน เรามักจะใช้โปรแกรมพื้นฐานอย่าง Excel และ Spreadsheet เป็นหลัก เพราะคนในทีมมักส่งไฟล์นี้มาให้เพื่อให้เราส่งกลับให้ไปทำงานต่อได้ง่าย สะดวกต่อการแก้ไข ทำเพิ่ม ซึ่งบางวันก็เปิดแค่โปรแกรมนี้อย่างเดียวก็ทำงานได้ยาว ๆ
สิ่งที่ได้เรียนรู้ในวันนี้
ทำงานทุกอย่างที่มีด้วยโปรแกรม Excel และ Spreadsheet
โดยสิ่งที่เราทำก็คือ
- Cleansing Data และ Preparation Data
- Statistical Analysis ด้วย Excel Function
- ทำ EDA และ Data Mining ด้วยเครื่องมือใน Analysis ToolPak
- ทำสรุปข้อมูลง่าย ๆ เร็ว ๆ ด้วย Pivot table และ Visualization
- สร้างตารางข้อมูลแบบง่าย ๆ แค่ Conditional Formatting Table
- Data Scrap จาก Website ลงในชีท
- ดึงข้อมูลจาก Third Party Platform ด้วยเครื่องมือ Supermetric
- ทำ Ad-hoc Report ส่งให้ลูกค้า
- ใช้ Modeling และ Prediction อย่าง Time Series Analysis, Linear Regression หา Correlation บางทีก็ใช้เพื่อหา Segmentation
- ต่อกับ Third Party Service Application เช่น Line Notify เพื่อแจ้งเตือนข้อมูลที่มีเงื่อนไขบางอย่างให้คนที่เกี่ยวข้อง
Day 150 วันที่ต้องใช้ Design Tool เพื่อสื่อสารกับ Dev. ด้วยตัวเอง
ไม่จำเป็นต้องรู้ทุกอย่างตั้งแต่วันแรกที่ทำงาน ในระหว่างการทำงานมักมีโจทย์ที่เราไม่เคยหาคำตอบมาก่อน บางอย่างก็อยู่นอกเหนือเส้นทางของ Data Analyst มีครั้งหนึ่งที่ทีมอื่นชอบดีไซน์ของแดชบอร์ดใน Balsamiq ที่เราทำไว้ แต่ Developer ไม่สามารถเอาไปใช้งานต่อได้ แล้วเราก็ไม่มี Designer ด้วย เราจึงลองใช้ Figma ที่สามารถให้ Dev. ทำงานต่อได้ (ซึ่งวิถีของ Designer มืออาชีพแนะนำให้ลองอ่าน 5 สิ่งที่เหล่า Designer ผู้น่ารักทำได้อีกนิด เหล่า Developer จะทำงานง่ายขึ้นเยอะเลยล่ะ อันนี้เลย)
สรุปงานที่ทำในวันนี้
ออกแบบ Dashboard ให้ Developer ด้วย Figma
โดยสิ่งที่เราทำก็คือ
- ด้วยความที่เราไม่มีคนที่รู้เรื่องนี้ในทีมเลย เราจึงเริ่มจากการหาเครื่องมือที่เหมาะสมสำหรับงานออกแบบแดชบอร์ดที่สามารถส่งต่อให้ Dev. ทำงานได้ที่ไม่ต้องติดตั้งและใช้งานได้ฟรี ซึ่งก็ลองอ่านรีวิวดูก็พบว่า Figma น่าจะเหมาะกับเรามากที่สุด
- เริ่มลงมือใช้งาน Figma สร้างแดชบอร์ดดีไซน์ตาม Wireframe จากที่เราร่างใน Balsamiq
- ก่อนส่งงาน ก็ตรวจสอบความเรียบร้อยด้วย Checklist เหล่านี้ เพื่ออำนวยความสะดวกให้เพื่อนร่วมโปรเจค
Day 179 วันที่กล้าลอง Complex Graph ที่สร้างคุณค่าต่างไปจากเดิม
ถ้าการทำเหมือนเดิมไม่ได้ตอบโจทย์สิ่งที่ทำอยู่แล้ว ก็ต้องหาวิธีใหม่ ๆ ซึ่งการทำงานจริงก็สามารถทดลองทำสิ่งที่ต่างไปจากเดิมได้นะ
ในวันหนึ่งเราพยายามจะสื่อสารกับลูกค้าว่าสิ่งที่เราเห็นผลรวมของข้อมูล แล้วตัดสินใจเปรียบเทียบ ตัดสินใจไปเลยอาจไม่ถูกไปทั้งหมด เช่น เข้าใจว่าช่องทางขายสินค้าได้คือ A ดังนั้นควรลดการทำโฆษณาช่องทางอื่น ๆ ไปเลย แต่ในรายละเอียดที่ซ่อนไว้คือลูกค้ามักจะรู้จักสินค้าจากช่องทาง B มากกว่า A แล้วค่อยไปตามรีวิวที่ C จากนั้นกลับมาซื้อที่ A แล้วลูกค้าที่ซื้อสินค้าในช่องทาง A ส่วนใหญ่แล้วต้องผ่านช่องทาง C หากลูกค้าอยู่ที่ช่องที่ B หรือช่องทาง A ก็มักจะไม่มียอดซื้อสินค้าเลย การตัดสินใจปิดช่องทางโฆษณาไปเลยโดยยังไม่ได้ทดสอบต่ออาจจะไม่เวิร์คก็ได้
สรุปงานที่ทำในวันนี้
ลองใช้กราฟแปลก ๆ เพื่อนำเสนอให้ลูกค้า
โดยสิ่งที่เราทำก็คือ
- จับคู่สิ่งที่ต้องการสื่อสารกับกราฟที่เหมาะสม
- เปรียบเทียบประสิทธิภาพการอ่านข้อมูลแบบเดิมและแบบใหม่
- ลองนำเสนอให้ลูกค้าฟัง
💡 Tip & Trick: ในบางครั้งการทดลองอาจนำไปสู่การวิจารณ์ว่าเข้าใจยากเกินไปและมีความเข้าใจผิดอยู่ แต่ข้อดีก็คือการนำมาสู่การถกเถียงใหม่ ๆ เพื่อพิจารณาร่วมกันว่าควรเปลี่ยนแปลงให้สิ่งเดิมแทนสิ่งใหม่หรือยึดตามสิ่งเดิม หรือทำควบคู่กัน
ตัวอย่างของการลองใช้กราฟแปลก ๆ กับลูกค้าก็พบว่าสามารถนำไปสู่การตัดสินใจที่ดีขึ้นได้ แต่บางครั้งกราฟแบบใหม่ที่สามารถให้ดูมิติที่ละเอียดมากเกินขึ้นก็ทำให้เข้าใจยาก และนำไปสู่การไม่กล้าตัดสินใจเช่นกัน
Day 183 วันที่หลายงานประดังเข้ามาแล้วทุกงานด่วนหมด
ในวันที่หลาย ๆ งานประเดประดังเข้ามาพร้อมกับ Timeline ที่ใกล้ ๆ กัน ในสถานการณ์ที่ปกติแล้วเรามักจะตกลงกับทีมก่อนว่าขั้นตอนการทำงานกับข้อมูลแต่ละขั้นตอนใช้เวลาประมาณเท่าไหร่ แต่ในสถานการณ์ไม่ปกติ อย่างเช่นกระบวนการซับซ้อนกว่าที่จะประเมินให้แม่นยำได้เช่น ฐานข้อมูลที่เราไม่มีสิทธิ์เข้าถึง, ข้อมูลที่ยังไม่ทำ Data Storage, Requirements ไม่ชัดเจน เราจึงต้อง Prioritize งานให้ดีและวางแผนการทำงานเป็นขั้นเป็นตอนให้มากที่สุด
สิ่งที่ได้เรียนรู้ในวันนี้
วางแผนการทำงานด้วย Task Management
โดยสิ่งที่เราทำก็คือ
- แบ่งงานเร่งด่วนออกจากงานด่วนปกติจาก Timeline ซึ่งงานแบบนี้มักมาจากลูกค้า ส่วนใหญ่เป็นงานเร่งด่วนมาก ๆ ที่ต่อรองได้ยาก ให้ลง Deadline เหล่านี้ใน Calendar เราเลย
- งานที่ไม่มี Timeline กำกับ เราจะต้องกำหนดระยะเวลาการส่งงานเอง ดังนั้นเราต้องประเมินด้วยการ Extract Tasks ออกมาให้เป็นขั้นเป็นตอน เมื่อประกอบกันทั้งหมดงานนั้นต้องใช้เวลารวมเท่าไร แล้วค่อยจิ้ม Deadline ที่ให้เราทำงานได้สะดวกไม่กระทบกับงานที่ลงตารางไว้แล้ว
- จัดกลุ่มงานที่ทำพร้อม ๆ กันได้เช่น Extract Data, Queries Data, Ac Hoc Report ที่ใช้ข้อมูลคล้ายกันให้เตรียมเวลาสำหรับทำทีเดียว
- ถ้าต้องต่อรอง ก็สามารถส่งงานบางส่วนที่เสร็จให้ก่อนได้เพราะเราจัดกลุ่มงานที่ทำพร้อมกันได้ไว้แล้ว ดังนั้นจะไม่ค่อยเกิดปัญหาขอเลื่อนวันส่งงานเพราะไม่มีอะไรเสร็จได้
Day 200 วันที่คิดว่าถ้าต้องสื่อสารกับคนที่ไม่รู้สถิติเลยต้องลงลึกแค่ไหน ?
วันหนึ่งที่เราต้องเข้าไปคุยกับทีมการตลาด ก่อนหน้านั้นทีมการตลาดก็มีพื้นฐานการวิเคราะห์ข้อมูลเบื้องต้นคือใช้ Excel ทำ Summary Statistic ได้ เข้าใจ Key Metrics สำคัญ ๆ แต่ไม่คุ้นเคยกับ Jargon ที่คนทำงานสถิติใช้กัน เมื่อเราต้องพูดถึงเรื่องการทดสอบสมมติฐานที่ไปไกลว่าการเปรียบเทียบข้อมูลตัวแปรเดียวระหว่างสองแคมเปญ เราต้องลงรายละเอียดที่มากขึ้น แล้วเราจะสื่อสารด้วยสถิติยังไงดี ?
สิ่งที่ได้เรียนรู้วันนี้
เมื่อต้องเล่าผลการวิเคราะห์สถิติให้กับทีมการตลาดในมุมมองของ Data Analyst มีความท้าทายหลายอย่าง
โดยสิ่งที่เราทำก็คือ
- หลีกเลี่ยง Jargon และเทคนิคที่เข้าใจยาก ๆ เช่น แทนที่จะพูดว่าเราทำ Hypothesis Testing ให้เราบอกว่าเรากำลังทดสอบประสิทธิของแคมเปญการตลาดแทน
- ใช้ Visualization เข้าช่วยเพื่อชี้ให้เห็นว่าสิ่งที่เล่ามาเมื่อกี้นี้สังเกตได้จาก Line Chart ที่ Landing Page B ในระยะยาวมี Number of Registers ที่มากกว่า Landing Page A
- เมื่อเล่าเสร็จให้ควรตอบคำถามได้ว่าเราทดสอบสิ่งนี้เพื่ออะไร และสุดท้ายควรแนะนำ Actionable Recommendations ได้ว่าทีมการตลาดควรทำอย่างไรต่อไป
- ในระหว่างการเล่าสถิตินี้ก็ควรเล่ากระบวนการคิดสมมติฐานด้วย สิ่งนี้สามารถเล่าได้ เช่น บอกเหตุผลว่าทำได้เราถึงตั้งสมมติฐาน (Hypothesis) นี้ด้วยการเชื่อมโยงกับสถานการณ์จริง เช่น ฝ่ายขายสังเกตว่าคนมักจะกด Register หน้า Landing Page ที่เป็น One Image มากกว่า Carousal จึงอยากทดสอบข้อสังเกตอันนี้
- สำหรับสมมติฐานการทดสอบ Null hypothesis (H0) คือสถานะตอนเริ่มต้นที่ Landing Page ทั้งสองแบบไม่มีผลต่อการดึงดูดให้คนลงทะเบียนซักหน่อย และ Alternative hypothesis (H1) คือสถานะที่เปลี่ยนไปการมี Landing Page ที่ต่างกันมีผลต่อการเลือกลงทะเบียนจริง ๆ นะ
- ในส่วนของการเลือกสถิติที่ใช้ทดสอบ, ค่า P-Value, Significant Level อาจไม่ต้องลงลงรายละเอียดมากนัก เน้นการสรุปประเด็นเลยว่าแคมเปญนี้มีประสิทธิภาพแค่ไหนเช่น ไม่มีประสิทธิภาพเท่าไหร่เลย หรือได้ผลดีแบบคาบเส้น
- การตีความผลลัพธ์ (Interpretation) อย่างการ Reject H0 ก็ไม่ต้องย้ำว่าเราปฎิเสธสมมติฐานตั้งต้น แต่ให้เราสรุปความไปเลยว่าการเปลี่ยน Landing Page ดีกว่า แล้วนำไปสู่ Next Step เลยว่าแล้วทีมการตลาดควรตัดสินใจยังไงกับผลการทดสอบที่เกิดขึ้น
Day 275 วันที่ต้องใช้ข้อมูลสมมติ (Implied Data)
ถ้าไม่มีข้อมูลจริงอยู่ เราก็มักจะใช้ข้อมูลทางอ้อมหรืออนุมานจากข้อมูลที่มีอยู่ซึ่งลักษณะของการใช้ข้อมูลแบบนี้จะถูกเรียกว่าข้อมูลโดยนัย ในโลกการทำงานจริงเราสามารถอธิบายสิ่งที่เกิดขึ้นจากข้อมูลประกอบ แต่เราไม่สามารถใช้ข้อมูลจริงเพื่อทำนายอนาคตได้ ชีวิตการทำงานของเราบางทีก็เกี่ยวข้องกับข้อมูลที่เราสมมติขึ้นประกอบจากหลักการสถิติและ Machine Learning
สิ่งที่ได้เรียนรู้ในวันนี้
งานเหล่านี้ที่มักเจอกับสถานการณ์ต้อง Implied Data โดยสถานการณ์ที่เป็นไปได้คือ
- ข้อมูลแหว่งหาย แล้วเราต้องทำให้สมบูรณ์ก่อนส่งให้ลูกค้า
- คิดตัวแปรใหม่หรือปรับปรุงตัวแปรเดิม ทำให้เราคำนวณใหม่ด้วยการใช้หลักการณ์คณิตศาสตร์ ตรรกะ หรือข้อมูลเดิมให้เกิดผลลัพธ์ที่สามารถตีความแบบใหม่
- Predictive Modeling เราใช้ข้อมูลในอดีตเพื่อพยากรณ์ไปข้างหน้าด้วยหลักการทางสถิติและ Machine Learning ซึ่งข้อมูลที่ได้มาก็จัดเป็นการ Implied Data
- Time Series Forecasting เราใช้ Observed Data Point ในอดีตแล้วคาดการณ์ไปข้างหน้าด้วยรูปแบบเหตุการณ์ในอดีต ซึ่งข้อมูลที่เราคาดการณ์ออกมาก็เป็น Implied Data
- Customer Behavior Analysis บ่อยครั้งข้อมูลประเภทนี้ที่เราใช้ในการทำงานก็คือข้อมูลที่อนุมานจากพฤติกรรมที่เคยเกิดขึ้นแล้ว
- Cluster Analysis เมื่อต้องจัดกลุ่มข้อมูลเราจะใช้ Machine Learning เพื่อช่วยจัดกลุ่มที่มีลักษณะพฤติกรรมที่มีรูปแบบเดียวกันอยู่ด้วยกัน บางทีถ้าไม่ใช้ ML เราก็ใช้การสังเกตความเหมือนด้วยตัวเอง อาจจะใช้สถิติเข้ามาช่วย
Day 292 วันที่ทำให้เรารู้สึก Insecure เพราะทำงานคนเดียว
ข้อนี้ไม่เกี่ยวกับการทำงานซักเท่าไหร่ แต่การเป็น Data Analyst ที่ทำงานคนเดียวก็ต้องเจอกับความรู้สึกวุ่นวายใจในชีวิตการทำงานของตนเอง ซึ่งเหตุผลที่ทำให้รูสึกเช่นนี้ก็มีหลากหลาย ไม่ว่าจะต้องจัดการกับงานที่ซับซ้อนหลายโปรเจค, ปัญหาของ Data Quality, Imposter Syndrome และ ความคาดหวังของลูกค้า โดยส่วนตัวเรามักจะแก้ปัญหานี้ด้วยการถอยหนึ่งก้าว เปลี่ยนจากภาพงานยิบย่อยให้มองภาพใหญ่แล้วค่อยแบ่งงานเป็นภาพย่อยอีกที ซึ่งแต่ละมักจะมีวิธีการรับมือที่ต่างกันออกไป วิธีนี้อาจไม่เหมาะกับทุกคนนะ ลองค้นหา the Mechanisms of Defense ดูเผื่อเป็นไกด์ไลน์ว่าเมื่อเกิดปัญหา เรามักแก้ปัญหาแบบไหน
สิ่งที่ได้เรียนรู้ในวันนี้
ปัญหาของ Data Analyst ที่ทำงานคนเดียว
โดยสิ่งที่เราทำก็คือ
- เมื่อเจอกับงานที่ซับซ้อนหลายโปรเจค เราจะพยายาม Break-down task ให้สามารถจัด Rating ความยาก-ง่ายของงานได้ แล้วเริ่มจากงานที่ยากที่สุดก่อนเผื่อเจอปัญหาระหว่างการทำงานจะได้หาทางแก้ทัน
- เมื่อต้องเจอกับปัญหา Data Quality ในการทำงานคนเดียว เรามักต้องเตรียมข้อมูลเองหรือขอข้อมูลจากคนนอกดังนั้นเบื้องต้นเราจะเช็คความสมบูรณ์ของข้อมูล สิ่งที่เป็นความผิดปกติ จากนั้นต้องรายงานให้ทีมรู้ปัญหาเบื้องต้นก่อน หลังจบงานก็ต้องทำ Document เพื่อชี้แจงกระบวนการทำงานและ Data Quality ให้ผู้ที่เกี่ยวข้อง
- เมื่อต้องเจอกับ Imposter Syndrome ที่รู้สึกว่าตัวเองยังขาดความรู้อีกมากแล้วทำให้เกิดการลำดับการทำงานไม่ค่อยได้ เมื่อเจอกับภาวะนี้เราจะลำดับงานทั้งหมดออกมาแล้วกำกับ Skill ที่คิดว่าต้องมีทำแบบนี้กับทุกงานหนึ่งรอบ รองที่สองค่อยพิจารณาดูว่าเรามี Skill นั้นรึเปล่า ถ้าไม่มีจะทดแทนด้วยอะไรดี
- เมื่อต้องเจอกับความคาดหวังของลูกค้า เรามักฝึกการตั้งคำถามบ่อย ๆ เพื่อลองเช็คงานที่ทำกับลูกค้าเป็นระยะ ๆ แล้วต้องสามารถอธิบายการทำงาน รวมถึงอุปสรรคที่เกิดขึ้น พร้อมกับลองเสนอความเห็นในการทำงานนี้ใน Next Steps แล้วขอ feedback จากลูกค้าดู
Day 310 วันที่ทีมเราต้องขยาย เราอยากได้ Data Engineer แบบไหนเข้ามาทำงานด้วย
ก่อนหน้านี้เราทำงานคนเดียวมาตลอด ซึ่งในช่วงเวลานั้นก็ได้ลองทำหลาย ๆ อย่าง สิ่งที่เป็นจุดที่อยากจะพัฒนาคือ Data Quality ดังนั้นเราจึงอยากได้ Data Engineer เข้ามาทำงานด้วยกัน แล้ว Data Engineer ที่ต้องทำงานกับ Data Analyst คนเดียวจะต้องเป็นแบบไหน ?
สิ่งที่ได้เรียนรู้ในวันนี้
ดูโปรไฟล์ Data Engineer ด้วยตัวเอง
โดยเราพบว่า Data Engineer มีหลายทักษะเช่น
- ETL/ ELT Engineer ต้องเป็นผู้ที่สามารถเชี่ยวชาญในการออกแบบการทำ ETL/ ELT Implement สามารถ Extract Data ได้หลายแหล่ง สามารถให้คำแนะนำว่าแบบไหนควรทำ Data Lake หรือควรทำ Data Warehouse
- Data Pipeline Engineer ที่เน้นการสร้างและดูแล Data Pipeline ให้สามารถเก็บข้อมูลได้แล้วสามารถนำไปใช้ต่อ และส่งต่อได้อย่างมีประสิทธิภาพ
- Database Engineer เรามีฐานข้อมูลอยู่เยอะมาก เราจึงอยากได้ผู้ที่สามารถในการ Maintain และ Scalability
- Data Governance Engineer ที่สามารถช่วยเรื่อง Data Quality, Security และ Privacy ได้
- สุดท้ายเราต้องการ Data Engineer ที่สามารถทำความเข้าใจกับ Business Role ได้และสามารถสื่อสารกับ Data Analyst ได้
Day 310 วันที่ต้องคุยงานกับทีม Outsource
การนัดคุยกันระหว่างทีม Outsource เพื่อขอความร่วมมือช่วยกันทำแดชบอร์ดหลักของบริษัทในครั้งนี้น่าจะเป็นครั้งที่สามแล้ว สองครั้งแรกล้มเหลว ข้อมูลบนแดชบอร์ดก็ไม่ถูกต้องซักที การขอตรวจสอบ Data Storage ก็วุ่นวายเพราะติดเรื่อง Privacy ในเมื่อทีม Outsource ที่มีแต่ Engineer และเราผู้เป็น Data Analyst ใครจะต้องเริ่มแก้ปัญหานี้ก่อนล่ะ
สรุปงานที่ทำในวันนี้
ทำแผนการสรุปวิธีการทำงานร่วมกันอย่างเป็นระบบ
โดยสิ่งที่เราทำก็คือ
- ทำแผนการสรุปวิธีการทำงานร่วมกันอย่างเป็นระบบ
ตัวอย่างแผนการทำงาน
| Phase | Task | Description | Responsible Party | Due Date |
|---|---|---|---|---|
| Initiation Phase | Identify Project Stakeholders | Identify and engage key stakeholders for the database project. | Project Manager | [Date] |
| Set Clear Objectives | Define project objectives, goals, and scope in alignment with organizational objectives. | Project Manager | [Date] | |
| Requirement Gathering Phase | Conduct Stakeholder Interviews | Schedule and conduct interviews to understand data needs, user requirements, and expectations. | Data Analysts | [Date] |
| Collect Existing Documentation | Gather existing documentation, reports, or data models providing insights into database requirements. | Data Analysts | [Date] | |
| Perform Data Analysis | Analyze sample data to gain insights into data structures, relationships, and data quality. | Data Analysts | [Date] | |
| Requirement Definition Phase | Define Functional Requirements | Document functional requirements, including data entry, retrieval, reporting, and specific functionality. | Data Analysts | [Date] |
| Define Non-Functional Requirements | Specify non-functional requirements like performance expectations, security, data retention, and compliance. | IT Security | [Date] | |
| Identify Data Sources | Identify sources of data to be integrated into the database (internal systems, external sources, etc.). | Data Engineers | [Date] | |
| Define Data Relationships | Document relationships between data entities (one-to-one, one-to-many, many-to-many) | Database Architects | [Date] | |
| Define Data Validation Rules | Specify data validation rules and constraints to ensure data quality and accuracy. | Data Engineer | [Date] | |
| Identify Reporting and Analysis Needs | Identify the types of reports, dashboards, and analyses required from the database. | Data Analysts | [Date] | |
| Requirement Documentation Phase | Create Requirement Documents | Document all requirements clearly using tools such as requirement documents, data dictionaries, and use cases. | Data Analysts | [Date] |
| Review and Validate Requirements | Conduct stakeholder review to validate documented requirements and address discrepancies or changes. | Stakeholders | [Date] | |
| Obtain Stakeholder Sign-Off | Seek formal sign-off from stakeholders to confirm acceptance of the documented requirements. | Project Manager | [Date] | |
| Implementation Phase | Communicate Requirements to Development Team | Share documented requirements with the development team, ensuring a clear understanding of project goals. | Project Manager | [Date] |
| Ongoing Maintenance and Review | Periodic Review | Establish a process for periodic review and updates to accommodate evolving business needs and technology. | Data Governance Team | [Date] |
| Quality Assurance and Testing | Develop Test Cases | Create test cases and scenarios based on requirements to ensure the database meets specified criteria. | Data Analyst | [Date] |
| Perform User Acceptance Testing (UAT) | Conduct UAT to validate that the database meets user expectations and requirements. | End-Users | [Date] | |
| Closure and Documentation | Close the Requirements Phase | Formalize the closure of the requirements phase and transition to development and implementation phases. | Project Manager | [Date] |
| Project Tracking and Reporting | Monitor Progress | Continuously monitor project progress and ensure development aligns with documented requirements. | Project Manager | [Date] |
| Report Status | Regularly report the status of requirement implementation to stakeholders and project management. | Project Manager | [Date] | |
| Post-Implementation Evaluation | Post-Implementation Review | After implementation, conduct a review to assess if requirements were met and if refinements are needed. | Stakeholders | [Date] |
Day 333 วันที่บริษัทไม่มี Enterprise tool ใช้ Opensource ก็ไม่ได้แย่
มีวันหนึ่งที่เราต้องเขียน R ต่อจากงานคนอื่น ซึ่งตอนนั้นก็ไม่เข้าใจว่าทำไมไม่ใช้ Enterprise tool เช่น Power BI, Tableau หรือ Looker Studio อะไรก็ได้ที่มีเพื่อสร้างกราฟที่ BI Tools มีน่าจะเร็วกว่า แต่ก็รู้ทีหลังว่างานบางอย่างก็ต้องจ้าง Outsource ช่วยดังนั้นเมื่อเขาไม่สะดวกใช้เครื่องมือเหล่านี้ การใช้ Opensource ก็เป็นอีกตัวเลือกนึงที่ดี สองเหตุผลที่คิดว่าใช่ก็เพราะ Customization และ Reproducibility อย่างแรกคือสร้างกราฟได้หลากหลายกว่า กราฟบางอย่างใน Enterprise BI Tools มีก็จริงแต่ต้องเสียเงินหรือเป็นเวอร์ชันทดลองที่จะหายไปเมื่อไหร่ก็ได้ กับอย่างที่สองคือส่งต่อให้เพื่อนเอาไปใช้หรือพัฒนาต่อได้ง่าย ถ้าเราไม่มีเวลาศึกษาให้เข้าใจทั้งหมด งั้นลองใช้ทางลัดดู
สรุปงานที่ทำในวันนี้
สร้าง Line Chart ด้วย Opensource อย่าง R
โดยสิ่งที่เราทำก็คือ
- หาเว็บไซต์ที่เป็นแหล่ง Resource ของ R User ในที่นี้เราเลือก r-graph-gallery ที่มีกราฟตั้งแต่ Basic ไปจนถึง Advance พร้อมตัวอย่าง Code
- ค้นหาการสร้าง Basic Chart อย่าง Line Chart ด้วย R Code
- เลือกตัวอย่างชนิด Line Chart ที่เหมาะสมกับงาน ซึ่งในเว็บไซต์นี้จะมีตัวอย่างหลายแบบ เช่น Basic Chart, Grouped Line Chart, Linear Trend เป็นต้น
- ซึ่งเราเลือก Linear Trend เพราะตอบโจทย์ Business Question มากที่สุด
- ศึกษารายละเอียดตัวอย่าง Code สิ่งที่ต้องสังเกตคือ Package ที่ต้องใช้ เช่น ต้องติดตั้ง ggplot2 (package สำหรับสร้างกราฟ) และ hrbrthemes (package สำหรับตกแต่ง themes) ต่อมาเราต้องมี Parameter อะไรบ้าง เช่น สำหรับการสร้างเส้นแนวโน้มต้องมีตัวแปร x, y ที่เป็น Data Type แบบตัวเลข และสำหรับการสร้างส่วน Scatter Plot ต้องมีตัวแปร x, y ที่เป็น Data Type แบบตัวเลขที่เหมือนกับเส้นแนวโน้ม และสุดท้ายสังเกต Aesthetic ที่ใช้ซึ่งในส่วนนี้เราสามารถดัดแปลงได้จาก R Community เป็นต้น
# Library
library(ggplot2)
library(hrbrthemes)
# Create dummy data
data <- data.frame(
cond = rep(c("condition_1", "condition_2"), each=10),
my_x = 1:100 + rnorm(100,sd=9),
my_y = 1:100 + rnorm(100,sd=16)
)
# Basic scatter plot.
p1 <- ggplot(data, aes(x=my_x, y=my_y)) +
geom_point( color="#69b3a2") +
theme_ipsum()
# with linear trend
p2 <- ggplot(data, aes(x=my_x, y=my_y)) +
geom_point() +
geom_smooth(method=lm , color="red", se=FALSE) +
theme_ipsum()
# linear trend + confidence interval
p3 <- ggplot(data, aes(x=my_x, y=my_y)) +
geom_point() +
geom_smooth(method=lm , color="red", fill="#69b3a2", se=TRUE) +
theme_ipsum()
- ทำเสร็จ บันทึกกราฟเป็นไฟล์รูปภาพ อัพเดต Code เผื่อมีคนเอาไปใช้ต่อ แบบนี้จะเอาไปใช้ตอนไหนก็ได้ ตัดปัญหา License หมดอายุไปได้
Day 365 วัน ๆ Data Analyst ใช้เครื่องมืออะไรบ้าง
สำหรับการทำงานจริงของ Data Analyst เรามักสามารถใช้เครื่องมือได้หลากหลาย เพราะเราให้ความสำคัญกับผลลัพธ์มากกว่าวิธีการ โดยเฉพาะถ้าทำงานคนเดียวก็จะมีอิสระในการเลือกเครื่องตามความถนัดที่เราคิดว่าเหมาะสมได้มากกว่าการทำงานเป็นทีม
ถึงอย่างไรก็ตามการใช้เครื่องมือที่หลากหลายมีข้อได้เปรียบกว่าการใช้เครื่องมือเดียวอย่างผู้เชี่ยวชาญเพราะเราเรียนรู้แค่พื้นฐานที่เป็นข้อได้เปรียบของเครื่องมือนั้น
ก่อนหน้านี้เราเชี่ยวชาญการใช้ Power BI เครื่องมือนี้จะเป็นหลักในการทำงานตั้งแต่ Extract Data, Load Data, Transformation Data, Data Visualization และ ทำ Machine Learning ร่วมกับ Python แต่สำหรับบางบริษัทไม่มี License เท่ากับว่าเราต้องใช้เครื่องมือ Opensource หรือ License Tool ที่บริษัทซื้อมาแล้ว ถ้าสามารถรู้พื้นฐานการใช้เครื่องมือเหล่านี้จะทำให้ชีวิตการทำงานราบรื่น
สิ่งที่ได้เรียนรู้ในวันนี้
เครื่องมือของ Data Analyst ตาม Tech Stacks ที่ใช้บ่อย ๆ
โดยสิ่งที่เราทำก็คือ
- กลุ่ม Programming Languages ประกอบด้วย R, Python, SQL
- กลุ่ม Packages for Data Analysis ประกอบด้วย R Library: dplyr, tidyr, ggplot2, caret, Python Library: Pandas, Numpy, Statsmodels**,** Matplotlib, Seaborn, Plotly, Beautiful Soup (web scraping HTML and XML)
- โปรแกมคำนวณคือ Excel, Spreadsheet
- กลุ่ม Database ประกอบด้วย Structure Data : SSMS, DBeaver อีกกลุ่มคือ Non-structure data : MongoDB
- กลุ่ม Business Intelligence ประกอบด้วย Power BI, Tableau และ Looker Studio
- กลุ่ม Notebook Environment ประกอบด้วย Jupyter Notebook, VSCode, R Studio
- Version Control: Git, GitHub
- Cloud Platforms ประกอบด้วย Google Big Query, AzureSQL
ขอบคุณภาพประกอบจาก Image by rawpixel.com on Freepik
อยากมาทำงานสาย Data ใช่มั้ย?
เรามี Workshop Data Interview ที่จะช่วยคุณเตรียมพร้อมสำหรับการสัมภาษณ์งาน ผ่านการทำ Case Interview
บทความที่เกี่ยวข้อง

เปิด Stack IDE สาย Data เครื่องมือไหนที่คนทำงานข้อมูลใช้กัน จากข้อมูลสถิติ Stack Overflow ปี 2025 และคนทำงานจริงในไทย พร้อมตัวอย่างการเลือกเครื่องมือที่เหมาะสม

สถิติกรมประมงเผย 25% ของสัตว์ทะเลที่จับได้เป็นปลาเป็ด ไม่ใช่อาหารคน ขณะที่หมึกกล้วย ปลาสีกุน ปลาทู ลดลงทุกปี วิเคราะห์วิกฤตประมงไทย 2559-2566 และอนาคตอาหารทะเล

เรียนรู้การทำ Diagnostic ด้วย SQL ผ่านโจทย์ทางธุรกิจที่จะได้ฝึกใช้ SQL ตั้งแต่ JOIN, GROUP BY, CASE และ WINDOW

การผสาน Dashboard และ Spreadsheet ช่วยเติมเต็มข้อจำกัดของแต่ละเครื่องมือ ทำให้ Workflow การนำเสนอข้อมูลยืดหยุ่นมากขึ้น